
Trouver toutes les lignes différentes entre deux tableaux Excel
")
Accueil > Bureautique > Excel > Excel Avancé > Trouver toutes les lignes différentes entre deux tableaux Excel





Pour partager cette vidéo sur les réseaux sociaux ou sur un site, voici son url :







Trouver les différences
Précédemment, nous avons découvert les méthodes Python compare et join afin de confronter les données de deux tableaux Excel. Les résultats ont été probants mais pas pleinement satisfaisants. Dans ce nouveau volet, nous allons découvrir la méthode Python merge pour extraire très explicitement les lignes différentes entre deux tableaux et renseigner sur leurs emplacements d'origine.
Classeur Excel à télécharger
Comme toujours, nous suggérons d'appuyer les travaux sur un classeur Excel existant.
- Télécharger le classeur differences-2-tableaux-python.xlsx en cliquant sur ce lien,
- Double cliquer sur le fichier réceptionné pour l'ouvrir dans Excel,
- Puis, cliquer sur le bouton Activer la modification du bandeau de sécurité,
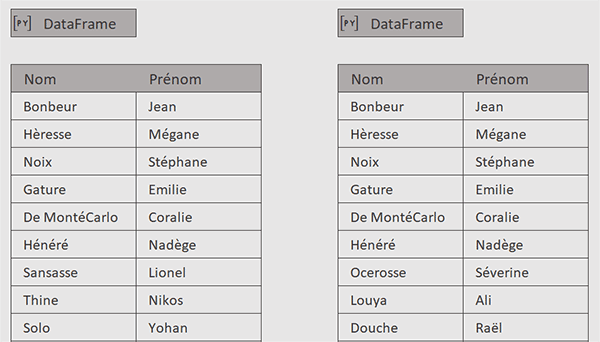
Nous découvrons deux tableaux Excel, encapsulés dans deux DataFrames en cellules respectives B3 et E3. Nous les avons nommés tab1 et tab2. Vous pouvez le constater en double cliquant sur leurs cellules.
Fusionner les tableaux
Nous l'avons dit, c'est la méthode Python merge qui permet de fusionner deux tableaux Excel représentés par deux DataFrames Python. Et nous entendons le démontrer tout de suite.
- Cliquer sur la première case de la grille d'extraction pour sélectionner la cellule H5,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Puis, débuter la syntaxe comme suit : fusion = tab1.merge(tab2,
Représenter toutes les lignes
Nous souhaitons que toutes les lignes soient recensées et des paramètres sont à renseigner.
- Taper une virgule (,) pour annoncer les paramètres à suivre,
- Puis, configurer les arguments suivants sans oublier de fermer la parenthèse de la méthode,
Nous obtenons un nouveau DataFrame après validation par CTRL + Entrée.
- A gauche de la barre de formule, cliquer sur la flèche orientée vers le bas,
- Dans les propositions, choisir Valeur Excel,
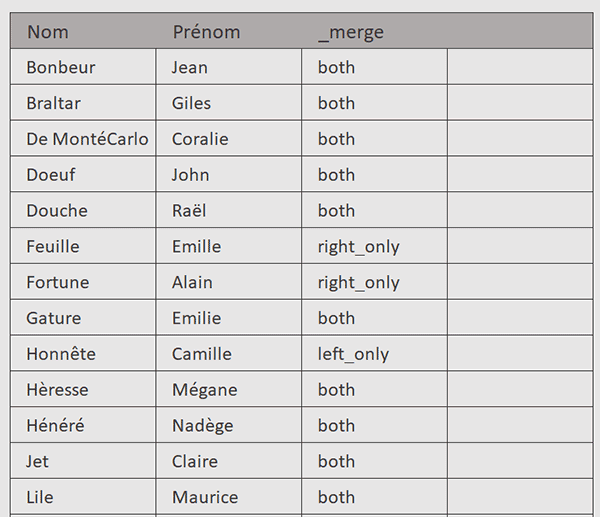
Nous obtenons une fusion avec une troisième colonne indiquant quand la ligne se trouve dans les deux tableaux (both), seulement dans le premier (left_only) ou seulement dans le deuxième (right_only). En effet, Le paramètre how="outer" inclut toutes les lignes des deux DataFrames, qu'elles soient présentes dans l'un, l'autre, ou les deux.
Le paramètre indicator=True ajoute une colonne _merge qui renseigne sur l'origine de chaque ligne. Ce sont précisément ces différences (left_only et right_only) que nous souhaitons isoler.
Isoler les différences
Pour ne conserver que les lignes différentes entre les deux tableaux, afin de pouvoir mieux les comparer, nous devons nous concentrer sur ces valeurs de sortie : left_only et right_only.
- Double cliquer sur la cellule H5 pour faire apparaître sa syntaxe,
- Cliquer à la fin de la syntaxe pour y placer le point d'insertion,
- Enfoncer la touche Entrée du clavier pour passer sur la ligne du dessous,
- Ajouter alors la ligne de code Python suivante :
- Valider l'adaptation de la formule par le raccourci clavier CTRL + Entrée,
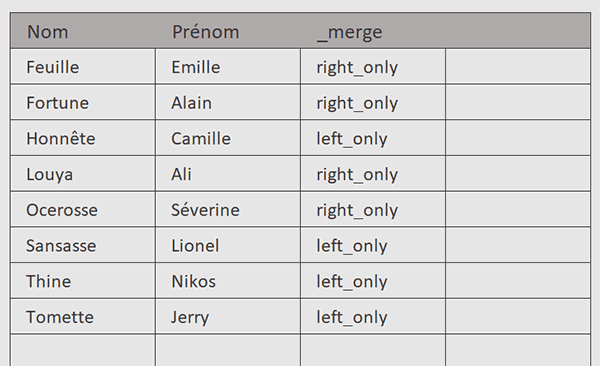
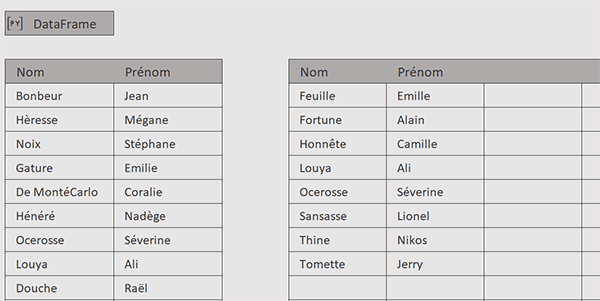
Et comme vous le constatez, l'extraction se résume aux lignes présentes dans le tableau de gauche mais qui n'apparaissent pas dans celui de droite et à celles qui sont présentes dans le tableau de droite mais qui n'apparaissent pas dans le tableau de gauche. Bref ,nous synthétisons toutes les différences entre les deux tableaux avec une syntaxe très simple et grâce à Python.
Vous constatez que les données sont naturellement triées sans avoir eu à utiliser la méthode Python sorts_values sur la colonne des noms. Il semblerait que la méthode merge de pandas effectue un tri interne pour optimiser la fusion.
Enfin, si vous souhaitez vous débarrasser de la dernière colonne (_merge) jugeant qu'elle est désormais futile, il vous suffit d'appliquer et comme nous l'avons déjà appris la méthode drop sur cette dernière, comme suit :
fusion = tab1.merge(tab2, on=["Nom","Prénom"], how="outer", indicator=True)
diff = fusion[fusion["_merge"].isin(["left_only", "right_only"])].drop(columns=["_merge"]).reset_index(drop=True)
Sur Facebook

Sur Youtube

Les livres

Contact

Mentions légales







