
Exclure les lignes différentes par formule Python
")





Pour partager cette vidéo sur les réseaux sociaux ou sur un site, voici son url :







Exclure les lignes différentes
Dans le volet précédent, nous avons découvert la méthode Python compare. Ici, c'est une autre méthode qui s'invite. Elle est un peu dans le même registre pour comparer plusieurs tableaux Excel. Elle se nomme join. Elle permet de réunir deux tableaux tout en excluant les lignes qui diffèrent. En d'autres termes, elle réunit et consolide les données communes.
Classeur Excel à télécharger
Nous suggérons d'appuyer l'étude sur un classeur Excel existant.
- Télécharger le classeur lignes-communes-2-tableaux.xlsx en cliquant sur ce lien,
- Double cliquer sur le fichier réceptionné pour l'ouvrir dans Excel,
- Puis, cliquer sur le bouton Activer la modification dans le bandeau de sécurité,
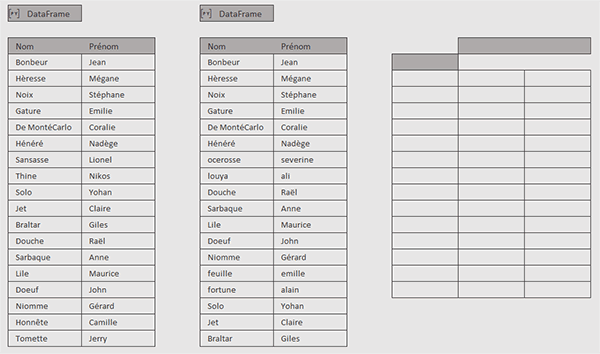
Nous trouvons deux tableaux Excel à comparer. Chacun est encapsulé dans un DataFrame Python en cellules B3 et E3 selon les syntaxes respectives suivantes : tab1=xl("B5:C23", headers=True) et tab2=xl("E5:F23", headers=True). Vous pouvez consulter les données qu'ils embarquent en cliquant sur l'un ou l'autre préfixe [PY]. Sur la droite, une grille vide est en attente de l'extraction des lignes communes.
L'index directeur
Pour cette extraction, nous devons utiliser les colonnes des noms comme index directeurs. Les différences se feront ainsi sur les colonnes des prénoms lorsque les noms sont identiques. Pour cela, nous devons utiliser la méthode set_index sur les deux DataFrame.
- Cliquer sur la case au-dessus de la grille d'extraction pour sélectionner la cellule H5,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Débuter la syntaxe comme suit : tab1.set_index("Nom", inplace=True),
- Enfoncer la touche Entrée pour passer à la ligne,
- Puis, réitérer sur le deuxième DataFrame : tab2.set_index("Nom", inplace=True),
- Valider la formule par le raccourci clavier CTRL + Entrée,
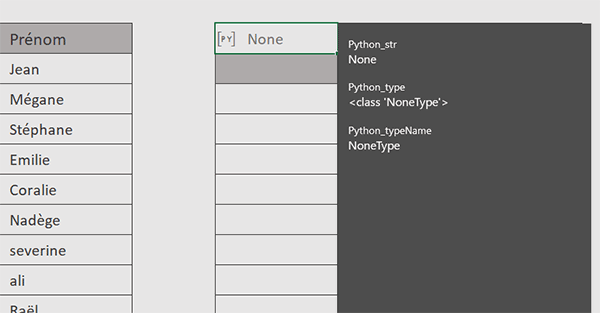
En réponse à ce stade, nous obtenons un objet vide ce qui est tout à fait logique. Nous l'avons dit, nous venons de définir l'index directeur (la colonne Nom) pour la réunion que nous allons opérer. C'est le paramètre inplace réglé à True qui indique que cette colonne devient l'index du DataFrame.
Réunir les tableaux
Maintenant, il est temps de découvrir la méthode Python join.
- Double cliquer sur la cellule H5 pour afficher son code,
- Cliquer à la toute fin de la syntaxe pour y placer le point d'insertion,
- Enfoncer la touche Entrée pour passer à la ligne,
- Puis, ajouter la ligne suivante : tab1.join(tab2, lsuffix="_tab1", rsuffix="_tab2"),
- Valider alors la formule par le raccourci clavier CTRL + Entrée,
- A gauche de la barre de formule, cliquer sur la flèche orientée vers le bas,
- Dans les propositions, choisir Valeur Excel,
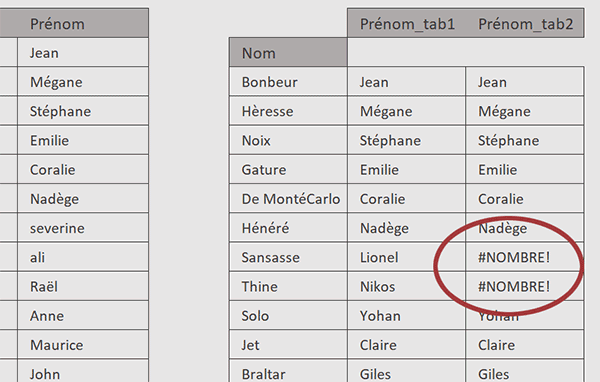
Eliminer les erreurs
C'est en éliminant les lignes portant ces erreurs que nous allons pouvoir produire l'extraction des personnes strictement identiques entre les deux tableaux. Et nous l'avons déjà appris, c'est la méthode Python dropna qui permet ce petit tour de magie.
- Double cliquer sur la cellule H5 pour afficher son code,
- Cliquer à la toute fin de la syntaxe pour y placer le point d'insertion,
- Appeler la méthode dropna comme suit :
- Valider l'adaptation par le raccourci clavier CTRL + Entrée,
Classer les résultats
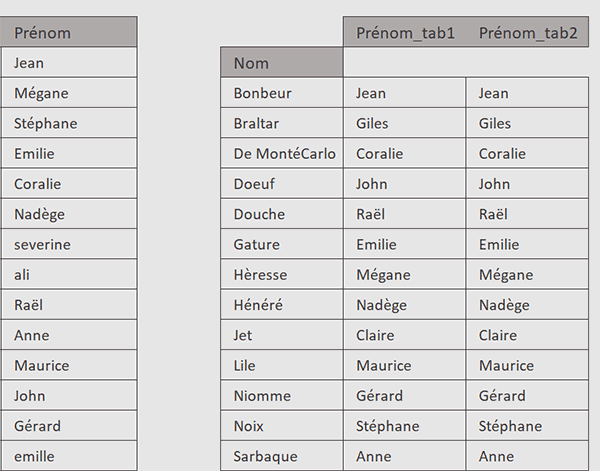
Pour y voir plus clair et pour une meilleure interprétation, il apparaît opportun de classer les résultats dans l'ordre croissant sur les noms. Pour cela, la méthode join offre un quatrième paramètre, certes facultatif mais qui permet d'influer sur le tri des données résultantes.
- Double cliquer sur la cellule H5 pour afficher son code,
- Cliquer juste avant la parenthèse fermante de la méthode join,
- Dès lors, régler l'argument sort comme suit :
- Valider la syntaxe par le raccourci clavier CTRL + Entrée,
Supprimer la colonne redondante
Pour peaufiner la solution et pour un résultat plus propre, nous souhaiterions supprimer la troisième et dernière colonne. Etant donné qu'il ne reste plus que les lignes identiques, elle fait office de répétition sur les prénoms. Et pour cela et comme nous l'avons déjà appris aussi, nous devons engager la méthode Python drop sur cette colonne reconnue par l'intitulé Prénom_tab2.
- Double cliquer sur la cellule H5 pour afficher son code,
- Cliquer à la toute fin de la syntaxe pour y placer le point d'insertion,
- Appeler alors la méthode Python drop comme suit :
- Valider la syntaxe finale par le raccourci clavier CTRL + Entrée,
Sur Facebook

Sur Youtube

Les livres

Contact

Mentions légales







