
Transformer un tableau Excel de colonnes en lignes
")





Pour partager cette vidéo sur les réseaux sociaux ou sur un site, voici son url :







Convertir Largeur / Hauteur
La méthode Python stack est très utile pour transformer un DataFrame en réorganisant les colonnes en niveaux d'index, soit en lignes énumérées. Cette technique permet de convertir des données de format large (Organisation en largeur) en format long (Organisation en hauteur), ce qui est souvent nécessaire pour certaines analyses ou visualisations.
Classeur Excel à télécharger
Pour les démonstrations, nous suggérons de baser l'étude sur un classeur Excel existant.
- Télécharger le classeur convertir-largeur-hauteur.xlsx en cliquant sur ce lien,
- Double cliquer sur le fichier réceptionné,
- Puis, cliquer sur le bouton Activer la modification dans le bandeau de sécurité,
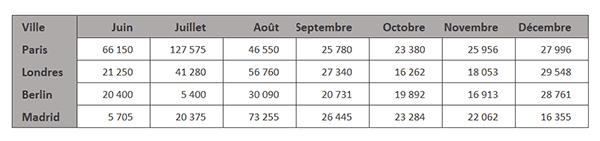
Il s'étend entre les colonnes B et I.
Sur la droite, une grille d'extraction est en attente de la restitution linéaire de ces informations par formule Python.

Elle s'étend entre les colonnes K et M.
Le DataFrame
Pour piloter ces données et comme nous en avons l'habitude, nous devons commencer par les encapsuler dans un objet Python, un DataFrame.
- Cliquer sur la première case grisée en haut à droite du tableau pour sélectionner la cellule K1,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Puis, débuter la syntaxe comme suit : tab =,
- Dès lors, sélectionner toutes les données du tableau source, ce qui donne :
- Valider la syntaxe par le raccourci clavier CTRL + Entrée,
Transformation linéaire
Nous l'avons dit, nous souhaitons restituer ces données à plat, les unes sous les autres, grâce à la méthode Python stack.
- Cliquer sur la première case vide de la grille d'extraction pour sélectionner la cellule K4,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Puis, débuter la syntaxe comme suit : lignes = tab.set_index('Ville').stack().reset_index(),
Dégrouper les données
Nous souhaitons maintenant restituer indépendamment et non plus de façon groupée les données sur les mois et les chiffres correspondants. Pour cela, nous allons exploiter la propriété columns pour énumérer les colonnes à la sortie pour la succession linéaire.
- A la suite de la syntaxe, enfoncer la touche Entrée pour passer à la ligne,
- Puis, ajouter la syntaxe suivante : lignes.columns = ['Ville', 'Mois', 'Valeur'],
- A la fin de la syntaxe, enfoncer la touche Entrée du clavier,
- Puis, terminer la syntaxe comme suit : lignes,
- Valider la formule par le raccourci clavier CTRL + Entrée,
- A gauche de la barre de formule, cliquer sur la flèche orientée vers le bas,
- Dans les propositions, choisir Valeur Excel,
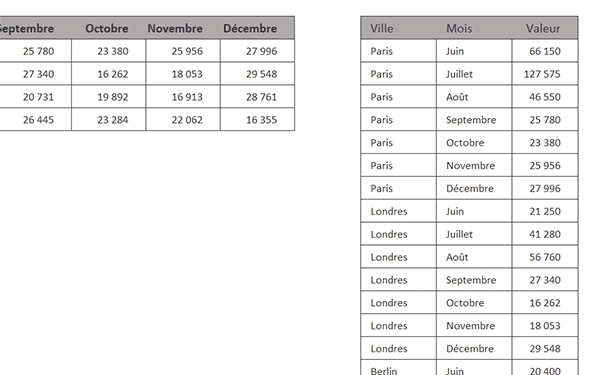
Nous obtenons bien une restitution "à plat" par villes répétées sur tous les mois désormais réitérés avec les chiffres en regard.
Sur Facebook

Sur Youtube

Les livres

Contact

Mentions légales







