
Supprimer les doublons et lignes répétées par formule Python Excel
")
Accueil > Bureautique > Excel > Excel Avancé > Supprimer les doublons et lignes répétées par formule Python Excel






Pour partager cette vidéo sur les réseaux sociaux ou sur un site, voici son url :







Les éléments uniques en Python pour Excel
Certes, depuis l'avènement d'Office 365, Excel offre une précieuse fonction native pour traiter les doublons. Cette fonction se nomme Unique. Mais Python pour Excel n'est pas en reste et c'est ce que nous allons découvrir.
Classeur Excel à télécharger
Nous proposons de baser la découverte sur un classeur Excel hébergeant une petite base de données.
- Télécharger le classeur Excel 02-unique.xlsx en cliquant sur ce lien,
- Double cliquer sur le fichier réceptionné pour l'ouvrir dans Excel,
- Puis, cliquer sur le bouton Activer la modification dans le bandeau de sécurité,
Sur la droite, des cases et grilles vides sont en attente de nos extractions par le biais de formules Python.
Le DataFrame
Comme nous l'avons appris à l'occasion du volet précédent, pour exploiter ces méthodes Python, nous devons premièrement encapsuler les données à traiter dans un DataFrame. Et nous allons attribuer un nom simple à ce DataFrame pour le piloter plus facilement.
- Cliquer sur la première cellule grisée pour sélectionner la cellule H2,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
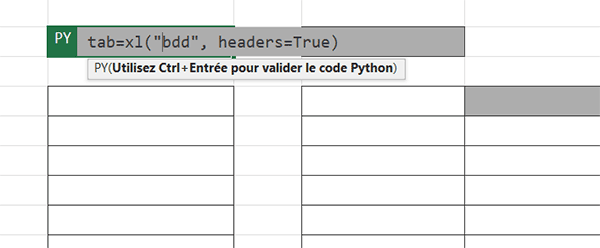
- Taper le début de syntaxe suivant : tab=,
- Dès lors, sélectionner une petite portion du tableau comme A1 à B2,
- Dans la barre de formule, remplacer la plage A1:B2 par le nom bdd,
Bdd est effectivement le nom que nous avions préalablement attribué à la base de données des activités de sorties. Vous pouvez le constater en déployant la zone Nom en haut à gauche de la feuille Excel.
Le DataFrame est créé. Rappelons-le, nous l'avons nommé tab. C'est désormais cet objet qui représente toutes les informations de la base de données des idées de sorties. C'est sur lui que nous allons maintenant pouvoir appliquer des méthodes Python pour purger les données.
La fonction ou méthode unique
La méthode python unique, lorsqu'elle est appliquée sur une colonne d'une source de données permet d'isoler toutes les valeurs sans leurs répétitions.
- Cliquer sur la première case de la première grille d'extraction pour sélectionner la cellule H4,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
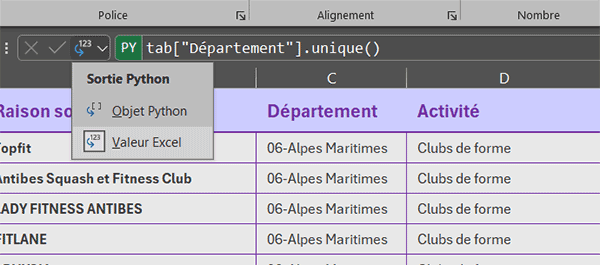
- Débuter la syntaxe comme suit : tab["Département"],
- Poursuivre la formule en appelant la méthode unique : .unique(),
- Valider la formule par le raccourci clavier CTRL + Entrée,
- A gauche de la barre de formule, cliquer sur la flèche dirigée vers le bas,
- Dans les propositions, choisir Valeur Excel,
C'est ainsi que nous transformons notre objet Python en liste de données. Et comme vous pouvez l'apprécier, nous obtenons bien une liste restreinte des départements purgés de leurs doublons.
Représenter plusieurs colonnes
Maintenant, nous souhaitons isoler les lignes qui sont vraiment uniques sur les paires Département / Ville. Il existe une technique Python pour créer un DataFrame représentant plusieurs colonnes choisies à partir d'un tableau source.
- Cliquer sur la deuxième case grisée pour sélectionner la cellule J2,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
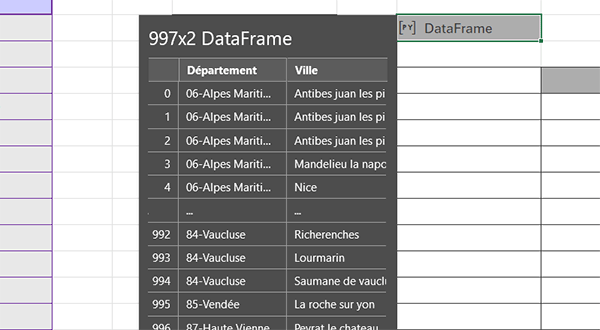
- Construire la syntaxe suivante : dv=tab[["Département", "Ville"]],
- Valider la formule par le raccourci clavier CTRL + Entrée,
Les lignes uniques
Pour extraire les lignes uniques sur plusieurs clés, ici pour exclure toutes celles qui proposent la même ville pour un même département, ce n'est plus la méthode python unique que nous devons employer mais la méthode drop_duplicates. Nous devons bien sûr l'appliquer sur l'objet dv que nous venons de construire, celui qui représente les informations sur les départements et les villes.
- Cliquer sur la première case de la grille d'extraction du dessous pour sélectionner la cellule J4,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Puis, construire la syntaxe suivante : dv.drop_duplicates(),
- Valider la formule par le raccourci clavier CTRL + Entrée,
- A gauche de la barre de formule, cliquer sur la flèche et choisir Valeur Excel,
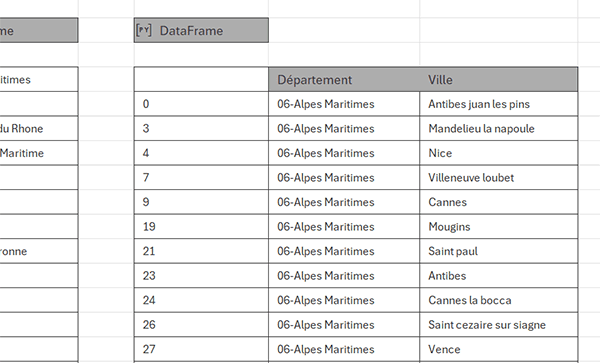
La première colonne, celle en plus et celle des numéros, renseigne sur la position de la ligne isolée dans la source de données.
Trier les données filtrées
Mais un petit détail chagrine pour l'interprétation des données dans la lecture linéaire. A l'intérieur de chaque département, les villes ne sont pas triées dans l'ordre croissant, ce qui ne simplifie pas la lecture. C'est pourquoi sur ces données restreintes, nous devons engager la méthode Python sort_values afin de diriger un tri avec deux clés.
- Double cliquer sur la cellule J4 pour faire apparaître sa syntaxe,
- A la fin, ajouter la méthode sort_values : .sort_values(by=["Département", "Ville"]),
Et comme vous pouvez l'apprécier dans chaque paire département/ville unique, les villes apparaissent désormais dans l'ordre croissant.
★ Le saviez-vous ? Pour supprimer définitivement des fichiers sans passer par la corbeille, il faut réaliser la combinaison MAJ(SHIFT) + SUPPR.
Sur Facebook

Sur Youtube

Les livres

Contact

Mentions légales







