
Supprimer la colonne des Index en Python pour Excel
")
Accueil > Bureautique > Excel > Excel Débutant > Supprimer la colonne des Index en Python pour Excel





Pour partager cette vidéo sur les réseaux sociaux ou sur un site, voici son url :







Supprimer la colonne des Index
Vous l'avez sans doute déjà remarqué, lorsque nous appliquons certaines formules Python sur des DataFrames encapsulant des données de tableaux Excel, celles-ci répondent par une colonne en plus en préfixe. Cette colonne non demandée, renseigne sur la position des lignes dans le tableau d'origine. Mais comment faire lorsque nous ne la souhaitons pas. C'est ce que nous allons démontrer dans ce nouveau sujet.
Classeur Excel à télécharger
Pour appuyer les travaux, nous suggérons de récupérer un classeur Excel existant.
- Télécharger le classeur supprimer-colonne-index.xlsx en cliquant sur ce lien,
- Double cliquer sur le fichier réceptionné pour l'ouvrir dans Excel,
- Puis, cliquer sur le bouton Activer la modification dans le bandeau de sécurité,
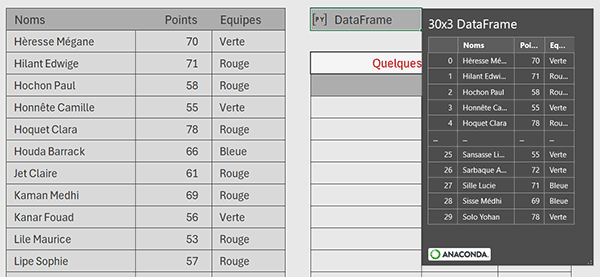
Nous découvrons un tableau des scores obtenus par des membres d'équipes. Sur la droite, nous avons encapsulé ce tableau dans un DataFrame Python nommé tab, selon la syntaxe suivante : tab=xl("B3:D33", headers=True).
Extraire aléatoirement
Sur la droite, dans la grille prévue à cet effet, nous souhaitons extraire aléatoirement 10 lignes à partir de ce tableau. Comme nous l'avons déjà appris, il s'agit d'embarquer la méthode Python sample sur ce DataFrame tab.
- Cliquer sur la première case de la grille d'extraction pour sélectionner la cellule F6,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Construire la syntaxe suivante : tab.sample(10),
- Valider la formule par le raccourci clavier CTRL + Entrée,
- A gauche de la barre de formule, cliquer sur la flèche orientée vers le bas,
- Dans les propositions, choisir Valeur Excel,
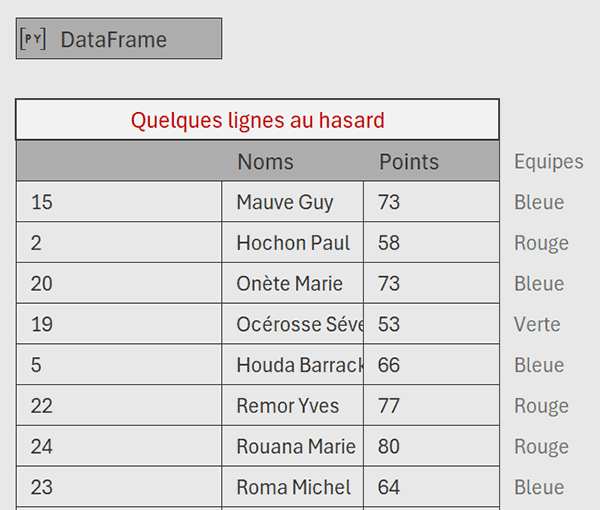
Mais, une colonne supplémentaire, celle des positions, apparaît en effet.
Supprimer les positions
La méthode Python qui permet d'ignorer cette colonne supplémentaire se nomme reset_index.
- Sélectionner de nouveau la cellule F6,
- Dans la barre de formule, cliquer à la toute fin de la syntaxe pour y placer le point d'insertion,
- Appeler alors la méthode reset_index comme suit : tab.sample(10).reset_index(drop=True),
- Valider la formule Python par le raccourci clavier CTRL + Entrée,
Classer les lignes extraites
Cerise sur le gâteau, maintenant que nous sommes débarrassés de cette colonne résiduelle, nous souhaitons classer l'extraction aléatoire dans l'ordre décroissant sur les scores. Et comme nous l'avons déjà appris, c'est la méthode Python sort_values que nous devons appliquer sur la colonne des points.
- Cliquer de nouveau sur la cellule F6 du calcul pour la sélectionner,
- Dans la barre de formule, cliquer juste après la parenthèse fermante de la méthode sample,
- Dès lors, appeler la méthode sort_values sur la colonne des points, comme suit :
Avec le paramètre ascending réglé à False, nous demandons un tri décroissant sur les scores.
- Valider enfin la formule Python par le raccourci clavier CTRL + Entrée,
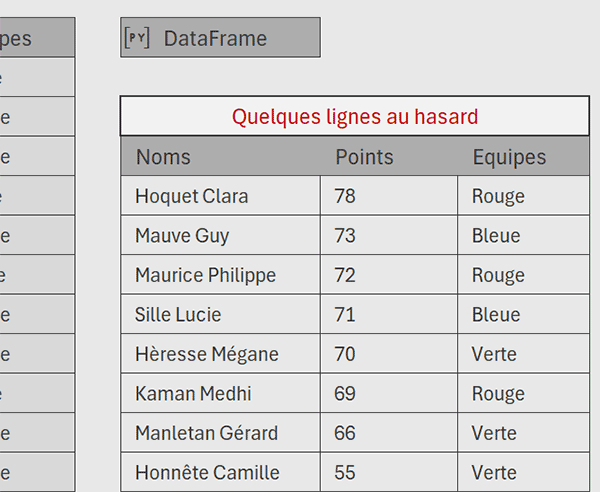
Nous obtenons bien une extraction aléatoire de 10 lignes à partir du tableau d'origine, débarrassée de la colonne des positions et triée dans l'ordre décroissant sur les points.
Sur Facebook

Sur Youtube

Les livres

Contact

Mentions légales







