
Regrouper les données d'un tableau Excel par formule Python
")
Accueil > Bureautique > Excel > Excel Avancé > Regrouper les données d'un tableau Excel par formule Python





Pour partager cette vidéo sur les réseaux sociaux ou sur un site, voici son url :







Regrouper les données dans un tableau Excel
Dans le sujet précédent, nous avons appris comment dégrouper les données d'un tableau de synthèse par formule Excel. Ici, nous prenons le contre-pied, sur un tableau où des données offrent des répétitions, nous allons effectuer des recoupements pour regrouper les données et offrir une synthèse efficace à l'interprétation. C'est l'occasion de rencontrer la méthode Python pivot.
Classeur Excel à télécharger
Comme toujours, nous suggérons de baser l'étude sur un classeur Excel existant.
- Télécharger le classeur reorganiser-regrouper-donnees.xlsm en cliquant sur ce lien,
- Double cliquer sur le fichier réceptionné pour l'ouvrir dans Excel,
- Puis, cliquer sur le bouton Activer la modification dans le bandeau de sécurité,

Nous travaillons à partir d'un tableau des résultats énumérés par matière pour chaque candidat entre les colonnes B et E. Les noms de ces candidats sont répétés car il y a plusieurs matières. En cellule G3, nous avons créé un DataFrame représentant ce tableau : tab=xl("B3:E33",headers=True). Sur la droite, une grille vide est en attente du traitement de ce DataFrame par formule Python pour regrouper les informations par identifiants et noms et ainsi livrer ces résultats sur une même ligne, pour chaque candidat dans des colonnes distinctes représentant les matières.
Les clés de regroupement
Nous devons premièrement regrouper les informations par personne. Chacune est reconnue par son identifiant et son nom. Il s'agit donc d'une paire.
- Cliquer sur la cellule G5 pour la sélectionner,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Puis, débuter la syntaxe comme suit : tab.pivot(index=['ID', 'Nom'],
Les colonnes de recoupement
Nous devons maintenant définir quels sont les thèmes de la colonne Sujet à répartir dans des rangées différentes.
- Taper une virgule (,) pour passer dans l'argument des colonnes de recoupement à construire,
- Puis, les identifier comme suit : columns='Sujet',
La synthèse
Enfin, nous devons indiquer sur ces recoupements quelle est la colonne source à consolider pour livrer ces synthèses par candidat et par matière. Il s'agit de la colonne nommée Score.
- Taper une dernière virgule pour passer dans le dernier argument de la méthode pivot,
- Désigner la colonne de consolidation comme suit : values='Score',
- Fermer la parenthèse de la méthode pivot,
- Valider la formule par le raccourci clavier CTRL + Entrée,
- A gauche de la barre de formule, cliquer sur la flèche orientée vers le bas,
- Dans les propositions, choisir Valeur Excel,
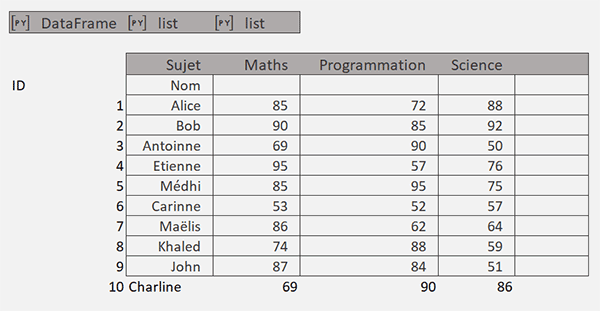
Nous obtenons bien le résultat escompté. Nous regroupons les informations sur la paire ID / Nom et consolidons les scores par matière mais un défaut subsiste. Vous constatez la présence des identifiants numériques en première colonne et surtout un décalage opéré en ligne à cause de l'étiquette Nom greffée au début de l'énumération.
Corriger les défauts
Pour corriger ces défauts, nous devons employer la méthode Python reset_index en bout de syntaxe. Cette méthode permet de transformer ces niveaux d'index en colonnes normales, pour simplifier les données résultantes, ce que nous souhaitons.
- Resélectionner la case du calcul en cliquant sur la cellule G5,
- Dans la barre de formule, cliquer à la toute fin de la syntaxe pour y placer le point d'insertion,
- Taper un point (.) pour appeler la méthode Python à suivre,
- Inscrire la méthode reset_index comme suit : reset_index(),
- Puis, valider l'adaptation par le raccourci clavier CTRL + Entrée,
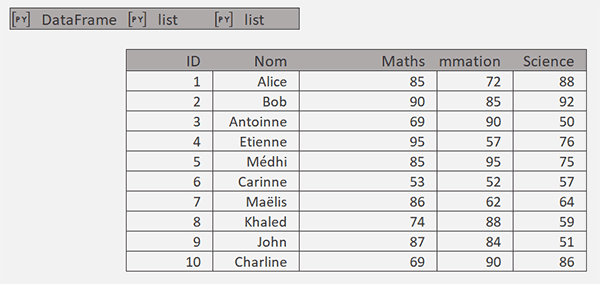
Comme vous pouvez l'apprécier, les défauts disparaissent et nous avons parfaitement réussi à regrouper et consolider les données par formule Python dans Excel avec une syntaxe très simple :
tab.pivot(index=['ID','Nom'], columns='Sujet', values='Score').reset_index()
Sur Facebook

Sur Youtube

Les livres

Contact

Mentions légales







