
Fréquences et répétitions par formules Python dans Excel
")
Accueil > Bureautique > Excel > Excel Avancé > Fréquences et répétitions par formules Python dans Excel





Pour partager cette vidéo sur les réseaux sociaux ou sur un site, voici son url :







Fréquences et répétitions
Dans ce chapitre, nous allons découvrir des méthodes Python d'analyses statistiques permettant notamment de compter les fréquences de répétitions des lignes dans un tableau Excel.
Classeur Excel à télécharger
Nous proposons de baser l'étude sur un classeur Excel existant.
- Télécharger le classeur frequences-et-repetitions.xlsx en cliquant sur ce lien,
- Double cliquer sur le fichier réceptionné pour l'ouvrir dans Excel,
- Puis, cliquer sur le bouton Activer la modification dans le bandeau de sécurité,
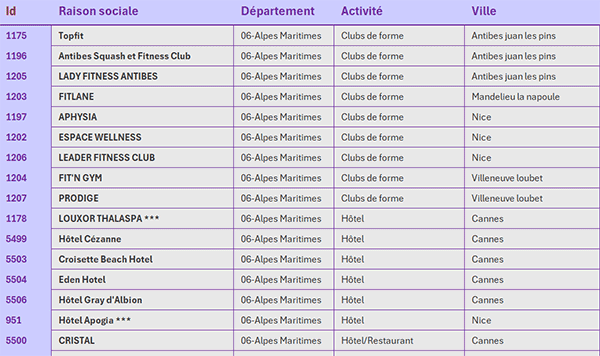
Nous travaillons à partir d'un tableau des activités de sorties recensées par département et ville notamment. Forcément, il existe plusieurs activités dans un même département mais aussi dans une même ville pour un département. Donc ces informations se répètent.
Synthétiser les départements et villes
C'est la raison pour laquelle nous souhaitons synthétiser les départements et les villes les plus représentés. C'est aussi la raison de la présence des petites grilles sur la droite entre les colonnes G et J. Un DataFrame est déjà présent en cellule H2. Nous l'avons nommé dv. Il représente la colonne des départements et celle des villes à partir du tableau des activités de sorties.
dv=xl("bdd", headers=True)[["Département", "Ville"]]
C'est la méthode Python mode qui permet d'extraire l'élément le plus représenté dans une série de données.
- Cliquer sur la première case vide pour sélectionner la cellule H4,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Débuter la syntaxe comme suit : repD=,
- Après le symbole égal (=), isoler la colonne des départements comme suit : dv['Département'],
- Taper un point (.) pour annoncer la méthode à suivre,
- Puis appeler la méthode Python mode : mode(),
- Dès lors, valider la formule par le raccourci clavier CTRL + Entrée,
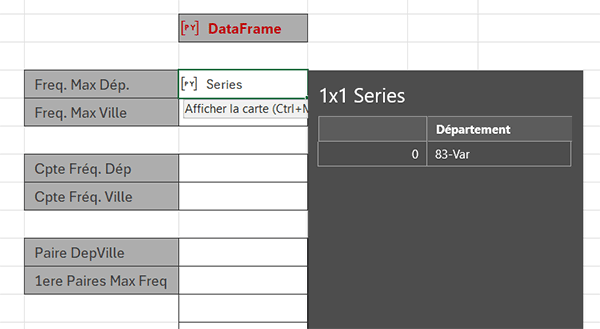
Nous obtenons un objet Python Series. Si vous cliquez sur son préfixe PY, vous constatez que le département le plus souvent représenté est celui du Var.
- Cliquer sur la case sous le premier calcul pour sélectionner la cellule H5,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Construire la syntaxe suivante : repV=dv['Ville'].mode(),
- Puis, valider par CTRL + Entrée,
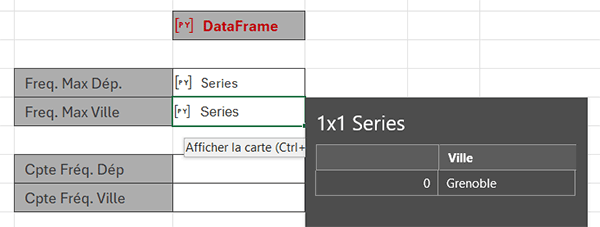
Nous obtenons un nouvel objet Python. Si vous cliquez sur son préfixe, vous apprenez que c'est la ville de Grenoble dans l'Isère qui est la plus souvent répétée.
Fréquences de répétitions
Ces renseignements sont intéressants mais nous aimerions connaître la fréquence de répétitions de ces données les plus récurrentes. Cette fois c'est la méthode Python value_counts() que nous devons employer là encore, indépendamment sur la colonne des départements puis sur celle des villes.
- Cliquer sur la cellule H7 pour la sélectionner,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Construire la syntaxe suivante : cptD = dv['Département'].value_counts()[repD],
- Puis, valider par CTRL + Entrée,
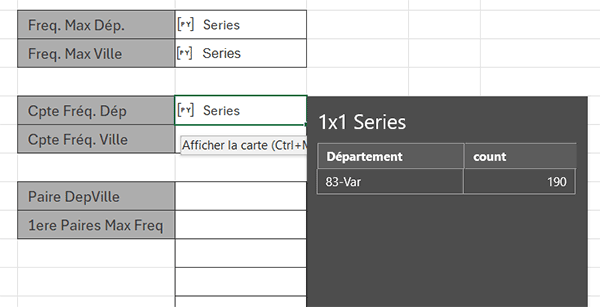
Nous n'avons plus qu'à adapter cette syntaxe sur la colonne des villes pour connaître la fréquence de répétitions de la ville la plus fréquente, qui est Grenoble comme nous le savons grâce au deuxième calcul.
- Cliquer sur la cellule H8 pour la sélectionner,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Construire la syntaxe suivante : cptV = dv['Ville'].value_counts()[repV],
- Puis, valider par CTRL + Entrée,
Fréquences par paires
Nous souhaitons maintenant aller plus loin pour connaître la combinaison Département / Ville la plus fréquente. Pour cela, nous devons passer l'assemblage de ces deux colonnes en paramètre de la méthode Python value_counts.
- Cliquer sur la cellule H10 pour la sélectionner,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Construire la syntaxe suivante :
Nous nommons donc notre DataFrame combinaison_freq.
- Puis, valider par CTRL + Entrée,
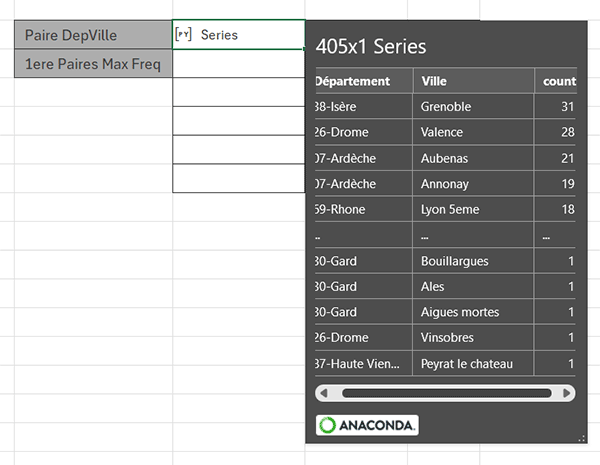
Si vous cliquez sur le préfixe de l'objet Series résultant, vous obtenez en effet un aperçu des fréquences de répétitions par paires Département / Ville.
Extraire les plus grosses fréquences
Pour parachever la solution, nous souhaitons extraire les quelques premières paires les plus fréquentes sur la base de cet objet que nous avons nommé combinaison_freq. Pour cela, nous devons énoncer le critère numérique sur la quantité dans la case rose en cellule I10 et l'encapsuler dans un objet Python en cellule voisine J10. C'est alors que nous pourrons exploiter ce DataFrame avec la méthode Python head sur ce critère.
- En cellule I10, taper le chiffre 4,
- En cellule J10, réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Dès lors, commencer la syntaxe comme suit : crn=,
- Puis sélectionner la cellule du critère, ce qui donne : crn=xl("I10"),
- Valider la syntaxe par le raccourci clavier CTRL + Entrée,
- Cliquer sur la cellule H11 pour la sélectionner,
- Réaliser le raccourci clavier CTRL + ALT + MAJ + P pour activer Python,
- Puis, construire la syntaxe suivante : combinaison_freq.head(crn),
- Valider la formule par le raccourci clavier CTRL + Entrée,
- A gauche de la barre de formule, cliquer sur la flèche orientée vers le bas,
- Dans les propositions, choisir Valeur Excel,
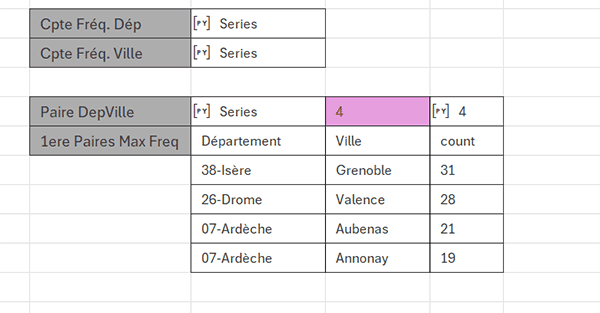
Nous obtenons bien une extraction des premières paires (Département / Ville) les plus fréquemment répétées dans cette base de données. Voilà donc pour ces formules d'analyses statistiques tout à fait remarquables grâce à Python dans Excel.
Sur Facebook

Sur Youtube

Les livres

Contact

Mentions légales







